iptables学习笔记 - 基础篇
导航
- iptables学习笔记 - 基础篇
- iptables学习笔记 - 规则篇:学习如何增删改查对应的防火墙规则
介绍
- 一般情况下,我们将
iptables、firewall、ufw等统称为防火墙,但是这些其实都只是防火墙管理工具,都是用户态命令,并非真正的防火墙,也就是说即使你将这些命令全部卸载掉,Linux的防火墙仍然是存在的 - 真正的防火墙框架,目前Linux内主流的是
netfilter框架,它存在于内核态 - 大部分Linux发行版都默认带有
netfilter和iptables组成最基础的防火墙套装,所以这里开始学习一些基本概念和命令 - 还有一点需要注意,
iptables命令行和iptables.service服务不是一个概念,服务的作用是自动管理部分规则,仅此而已,也就是说即使没有开启iptables.service,也不影响手动操作命令进行防火墙配置。本文中不讨论服务的机制,所以不会去操作服务相关的任何内容。
Netfilter Hooks
Linux中netfilter提供了5个hook点,可以理解为5个检查站,网络包进入Linux后在通过这些检查站时,会按照配置的规则依次进行检查,从而确定是否对此网络包进行某些动作
这五个分别是:
PREROUTING: 接收的包刚进入内核协议栈时,由NF_IP_PRE_ROUTING的hook点触发动作INPUT: 通过路由判断该网络包的目的地是本机,则经过此站点,由NF_IP_LOCAL_IN的hook点触发动作FORWARD: 通过路由判断该网络包的目的地不是本机,而是其他设备,则经过此站点,由NF_IP_FORWARD的hook点触发动作OUTPUT: 本地产生的要发往其他设备的包,在进入内核协议栈时经过此站点,由NF_IP_LOCAL_OUT的hook点触发动作POSTROUTING: 所有要发出的包在最后会经过此站,由NF_IP_POST_ROUTING的hook点触发动作
这里用朱双印前辈的图,一目了然:
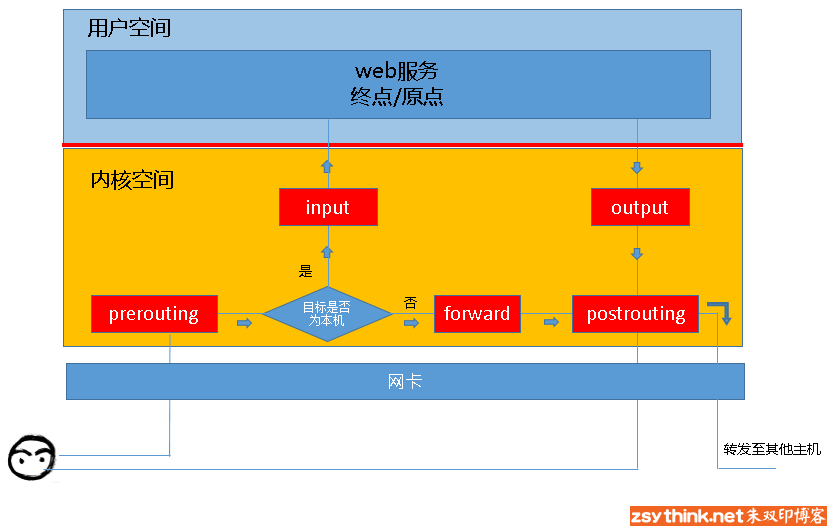
那从图片上就可以看出来一个包不会把五个站点全部过一遍,而是根据其流程,会经过特定的站点:
到本机某进程的报文:PREROUTING -> INPUT
过本机转发的报文:PREROUTING -> FORWARD -> POSTROUTING
由本机的某进程发出报文:OUTPUT -> POSTROUTING
iptables Chains (链)
上小节说了网络包进入系统后会经过不同的检查站,会通过不同的规则进行检查,实际场景中每个检查站的规则有很多条,会按照顺序依次进行匹配,这些规则依次排列就是iptables chain链
比如PREROUTING: 规则1 -> 规则2 -> 规则3 -> 规则4 -> 规则5 -> 规则6 -> 规则7 -> 规则8 -> 规则N
那对应的5个hook点,则存在默认的5条Chain:
- Chain PREROUTING
- Chain INPUT
- Chain FORWARD
- Chain OUTPUT
- Chain POSTROUTING
iptables Tables (表)
在检查点的规则按照其种类可以进行划分。
举个例子:比如一个货车开进了高速检查站,这时候要依次按照规则进行检查,规则1有没有超载,规则2有没有携带非法物品,规则3有没有套牌,规则4有没有年检合格,规则5有没有酒驾,规则6驾驶证有没有到期等等
那其中规则1,3,4都是检查车辆的,可以划分为一类,写在一张表上,这张表叫车辆合格检查表
规则5,6都是检查驾驶员的,可以划为一类,这张表叫驾驶员检查表
规则2也是一类,可以划分在非法物品清单
这个时候比如要新加一个规则叫驾驶员年龄检查,那直接将该规则加到驾驶员检查表上就可以,其他表就不用看了,这种就很方便
iptables tables就是这个理解。把具有相同功能的规则整合成的集合,叫做“表”
iptables将规则种类划分为5大类
filter
由内核模块iptables_filter提供功能
负责过滤,根据规则来确定这个网络包是否放行还是拒绝还是其他动作,这是最常用的table之一
nat
由内核模块iptable_nat提供功能
用来实现网络地址转换的规则表,网络地址转换不在本文详细探讨,这里不解释
mangle
由内核模块iptable_mangle提供功能
mangle修正。用来修改报文的IP头,可以拆解报文进行修改,之后重新封装
raw
由内核模块iptable_raw提供功能
在打开了连接跟踪机制的环境中,这张表的规则功能只有一个,就是取消匹配的包上的连接跟踪机制,让其不受到连接跟踪机制的限制
security
由内核模块iptable_security提供功能
设置包的selinux上下文标签,特定场合下使用
表链关系
首先不是每个检查站都存在所有表,那么每个hook点都有那些表并且每个表的匹配顺序是怎样的,这里用Justin Ellingwood 前辈的表格来进行展示
| Tables ↓ / Chains → | PREROUTING | INPUT | FORWARD | OUTPUT | POSTROUTING |
|---|---|---|---|---|---|
| 路由选择 | ✅ | ||||
| raw | ✅ | ✅ | |||
| 连接跟踪 | ✅ | ✅ | |||
| mangle | ✅ | ✅ | ✅ | ✅ | ✅ |
| nat(DNAT) | ✅ | ✅ | |||
| 路由选择 | ✅ | ✅ | |||
| filter | ✅ | ✅ | ✅ | ||
| security | ✅ | ✅ | ✅ | ||
| nat(SNAT) | ✅ | ✅ |
当一个包触发 netfilter hook 时,匹配过程将沿着列从上到下依次执行
结合这张表和上面小节的过程举例:
对于收到的并且目的地是本地的包首先会经过PREROUTING上的raw、mangle、net table;然后通过INPUT上的mangle、filter、security、nat table,最后到达用户态某个进程
规则 rules
概念:根据指定的匹配条件来尝试匹配每个流经此处的报文,一旦匹配成功,则由规则后面指定的处理动作进行处理;
前面一直在说规则,其实就是检查项,检查网络包,如果符合这条规则所描述的,表示匹配到了这条规则,那么就执行这条规则对应的动作。
比如检查站匹配到了货车超载了,那么就该罚款罚款,该阻拦阻拦,就这个意思。
匹配条件
基本上一个包的任何特征都可以当作匹配条件进行匹配
根据完成匹配功能的模块不同,一般分为基本匹配条件和扩展匹配条件
常见的匹配条件有:源或者目的IP、包中使用的协议、源或者目的端口号等
处理动作
处理动作有很多种,比如放通或者拒绝,又或者交给其他规则处理等等,这里列举常见的一些动作:
- ACCEPT:允许数据包通过,放通后不会再去匹配hook点上其他规则
- DROP:直接丢弃数据包,不给任何回应信息
- REJECT:拒绝数据包通过,必要时会给数据发送端一个响应的信息,客户端刚请求就会收到拒绝的信息
- SNAT:源地址转换,解决内网用户用同一个公网地址上网的问题
- MASQUERADE:是SNAT的一种特殊形式,适用于动态的、临时会变的ip上
- DNAT:目标地址转换
- REDIRECT:在本机做端口映射
- LOG:记录日志信息,然后将数据包传递给下一条规则,也就是说除了记录以外不对数据包做任何其他操作,仍然让下一条规则去匹配
参考









